マテリアルズインフォマティクス【布村紀男】
これまでの物質・材料の研究開発では、研究者・技術者の経験や勘や偶然性に依存してきました。そのため、新たな物質・材料を開発するためには膨大な時間と研究開発費が必要になります。しかし、近年、実験や計算シミュレーション等の大量なデータを解析し、物質・材料開発を高度化・高速化しようとする試みが行われています。マテリアルズインフォマティクス(MI)は、ひとことで言えば、「材料開発のための情報学」と捉えることができます。MIは、高精度・高効率な計算を利用して、材料特性の大規模なデータベースを分析する材料科学の結果として得られた分野です。検索キーワードとして、「マテリアルズインフォマティクス」をGoogle Trendsで調べてみたところ、2014年ごろから徐々に増加していることがわかります。(図1)この傾向はディープラーニング、ニューラルネットワーク技術の発展に象徴される第3次人工知能(AI)ブームやビッグデータ解析・活用に深く影響を受けていると思われます。さらに本格的にAlの実用化が始まった時期とも関連しています。
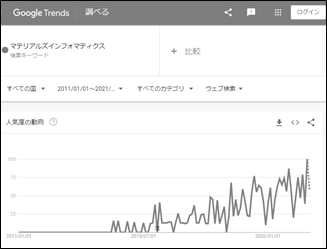
図1. 「マテリアルズインフォマティクス」のGoogle Trends
このMIを支える技術として、コンピュータの性能向上とともに、めざましい発展を遂げた機械学習を中心としたAI技術があげられます。機械学習とは、計算機にデータ分析を行わせ、経験則やパターンを自律的に認識させ、分類や予測を行うことです。最近では、従来の統計モデルに加えてディープラーニングやニューラルネットワークなどのより高度な計算手法が連携してMIで用いられています。
MIは機械的、電子的、熱力学的、輸送特性など多くの無機材料特性の研究に適用されています。さらに、光起電性材料、エネルギー貯蔵用材料、触媒/光触媒、熱電材料、高温超伝導体、高エントロピー材料および金属ガラス合金など、さまざまな材料用途分野で使用されています。早期の成功事例として、京都大学とシャープ株式会社によるLiイオン電池正極材の物質設計があげられます。1) この研究では、さまざまな置換元素の数千種類の組合せでの安定構造についてLiイオンが挿入、脱離する場合の体積変化を特性として計算して最適な置換元素を探索しました。構造と特性を関連づけることによりMIから予測された最適な組成の材料を試作して実験を行い、電池寿命が延びることが実証されました。
我々の計算材料学研究室でも、卒業研究として「アルミニウム合金における時効硬化現象の機械学習モデル作成」2) というテーマでMIに取り組んでもらいました。その内容について、紹介します。研究対象は、アルミニウムサッシ材や車両用車体材料、溶接構造用材料として注目されているAl-Mg-Si系合金(6000系アルミニウム合金)としました。この合金は、時効硬化型のアルミニウム合金で、熱処理や添加元素により硬さが大きく変わることが知られています。この研究では合金の硬度における添加元素、時効温度の影響について機械学習を用いて解析を行い、モデルを作成しました。機械学習の主な手順(ワークフロー)は次のようになります。
(1) データの準備(データ収集)
(2) 機械学習手法の選択(分類、回帰、クラスタリングなど)
(3) 前処理 (データの精査、データ拡張、学習 評価用にデータ分割)
(4) モデルのトレーニング(パラメータチューニング、学習)
(5) モデルの評価(テストデータを用いて学習したモデルの予測性能を評価、新規データの予測)
Al-Mg-Si系合金の既存データセットが無いため、論文から元データを抽出し、そのデータから時間、温度、硬度、添加元素を項目としたデータセットを作成しました。また、作成したデータセットの解析にはscikit-learnを用いました。データ分割には、全体のデータを訓練データ、検証用データ、テスト用データに分割してモデルの精度を測定するホールドアウト法を用いました。ここで、訓練データはモデルの学習、検証データはパラメータ調整、そしてテストデータは最終評価に使用されます (図2)。
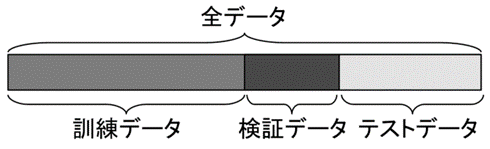
図2. ホールドアウト法(データ分割)
作成したモデルは、R2決定係数で評価を行いました。このR2決定係数はデータへの当てはまりの妥当性を評価し、1に近いほど実際のデータに当てはまっていることを示します。

訓練データに適合しすぎて、テストデータに対して正答率が低くなる現象の過学習があります。それを抑制する方法は、(1)学習データ数を増加、(2)正則化の2つです。今回は過学習を防止するために正則化を実施し、Ridge回帰を使用しました。
図3に各項目の相関についての結果を示します。白色に近いほど正の相関を持ち、黒色に近いほど負の相関を持ちます。強い相関を示しているペアは、Al vs. HV (-0.61), Al vs. time (0.44), Mg vs. HV (0.44), time vs. HV (-0.52) だとわかりました。今回は元素の添加量に着目したために、相関の強いAl(元素量)とHV(ビッカース硬さ)に対して機械学習モデルを作成しました。
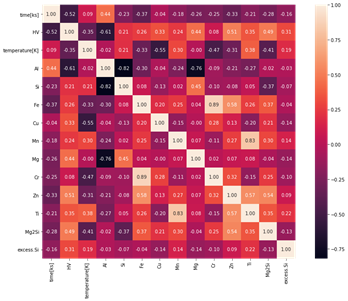
図3. 各特徴量のヒートマップ
表1は100-Al(mass %) vs HVの多項式回帰(Ridge回帰)の結果です。MAEは平均絶対誤差を表します。alphaはハイパーパラメータと呼ばれ、この値によりモデルの精度が大きく異なります。そのため、指定した範囲を網羅的に探索するグリッドサーチ(図4)をalphaに対して実施しました。図5に多項式回帰(Ridge回帰)のグラフを示します。
表1 Ridge回帰の結果

今回作成したモデルからは添加量における最大硬度とピーク時間を予測できます。 しかし、予測精度は高くなく、過学習が発生していると思われます。過学習を防ぐために正則化を行いましたが、依然として決定係数の差が大きい結果でした。その原因は訓練データが不足しており、学習が不十分となってしまったからだと考えられます。 決定係数を改善し、精度を向上させるには以下の方法を試す必要があります。(1)データ数の増加、(2)新たな特徴量を追加、(3)データセットの偏りを防ぐ、の3つです。具体的な改善方法として、(1)については、より多くの論文からデータ点を抽出する必要があります。(2)は、他の元素との影響を調査することです。使用する方法は重回帰分析、交互作用項の追加となります。(3)は、交差検証の適用です。そして、予測精度の向上と適用範囲の拡大のためには、信頼性の高いデータベースの拡充が不可欠であると思われます。
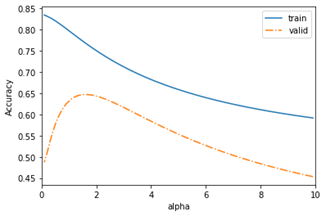
図4. グリッドサーチ(Ridge回帰)
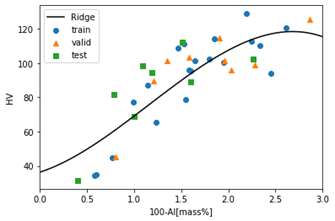
図5. 多項式回帰(Ridge)結果
本稿でお見せした研究結果はデータ数が少なく、予測精度も高くないもので興味深い結果からは程遠いものでした。多くの問題点や課題が残されていますが、改善策を適用することで、今後はもう少し良くなるものと思っています。コンピュータの最近の話題として、先頃、IBMが開発した量子ゲート型と呼ばれている汎用タイプの量子コンピュータが国内に初めて設置され稼働し、商用利用の開始が報道されました。もちろん、MIをはじめとする材料開発への利用も期待されています。量子コンピュータは、従来のコンピュータで用いられる0, 1のビットを量子ビットという重ね合わせの原理により0と1を同時に表現できため高速化・高度並列化処理も期待されており、今後は大きく発展することは確実です。
参考文献
1) https://www.nature.com/articles/ncomms5553
2) 中村哲也 令和2年度 材料機能工学科 卒業研究論文
3) 株式会社システム計画研究所 編「Pythonによる機械学習入門」(オーム社 2016).
4) 木野日織, ダム ヒョウ チ「Orange Data Miningではじめるマテリアルズインフォマティクス」(近代科学社 2021).